

Physical Science

Error Detection on Noisy Quantum Devices

Characteristics of Geomagnetic Storms and Their Drivers

Evaluating and Developing Tools for Open Source Underwater Acoustic Databases

Baltimore at Risk: Strengthening Soil with Natural Biopolymers

Aerospace and Space-Related Engineering

The Success of Flight Begins on the Ground: Designing Non-Flight Mechanical Systems for Space Missions

AntHill: Designing a Futuristic Lunar Rover that Helps Establish Long-Term Human Prescence on the Moon

NOVA: Amateur Weather Satellite Simulator

Modeling GPS for Mars

Revolutionizing Space Communication Testing

Autonomous Safe-Landing Drone with Machine Learning-Based Detection and Navigation

Application of Fault Management Engineering to Spacecraft Design

Mini COTS Dragonfly Avionics Box

Constructing Dragonfly: Engineering the Dragonfly Assembly Flow

Dragonfly MMRTG Integration: Fairing Simulator Assembly
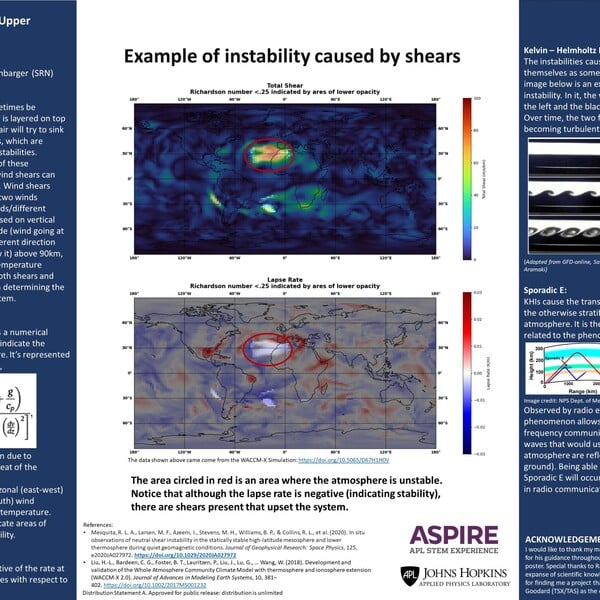
Analysis of Neutral Wind Shears in the Low Thermosphere

SEEcrets Revealed: Photodiode Space Radiation Vulnerability Exposed Through Pulsed-Laser Single Event Effect Testing

Applying Fractional Calculus to Autonomous Control of Flight Systems

Engineering

Computer-Controlled Digital Embroidery Machine for eTextiles

Polyurea Aerogels for Body Armor Augmentation

Hyperspectral Imaging: The Solution to Your Grainy Images

Identifying Aircraft Type Using ADS-B Transponder Phase Information

Electric Unfolding Rotorcraft Observational Platform Armament (EUROPA)

Quadcopter Digital Twin and Optimization

Experimental Rope Drive Testing for Continuous Chromatography

Low Budget Embedded System Synthesizer Design for Improved Music Education Opportunity

Ambient Intelligence for Patient Care Environments

Free-Space Optical Comms: How Lasers Can Transmit Data

Programming and Computer Science

A Spotify Data-Driven Web App for Clustering Tracks Across Eras

Plug-and-Play Robotics: Modular Sensor Streaming for Any Mission

SmartSched: Empowering Business Owners and Clients Through Seamless Appointments

Gitlab Ticket Creation Tool

Math and Data Analysis

How Do Brains Develop? Insights into Neurological Development from Electron Microscopy Data

Modeling and Analysis of Radar Beams Intersection

Modeling and Mitigating Obesity Spread Using Graph Theory and Decentralized Control

Strategic Tracking with Conflicting Filters: A Study of Kalman and Particle Filters in Nonlinear Game-Theoretic Systems

IT and Cybersecurity

Crack The Hashword - Using Reinforcement Learning For Faster Password Cracking

VictimVM: Misconfiguring a Virtual Machine to Develop a Hacker Mindset

Insider Threat Analysis and Direct Access Forensics

Environmental, Earth and Life Sciences
-with-AI-Optimized-Motor-Vibration.jpg)
Cost-Effective Fabrication of Hollow Fibers Using Selective Laser Sintering (SLS) with AI-Optimized Motor Vibration

CT Image-Based FE Modeling for Femoral Lesion Assessment

AI and Machine Learning

Automatic Speech Recognition: Sanskrit to English

Can AI Really Do Physics? Investigating AI Agents' Conceptual and Mathematical Reasoning Through Textbook Physics Problems

Aerial Imagery Reconnaissance for Collaborative Search & Rescue

Diagnosing the Problem: Automated Metrics for Evaluating AI-Generated Medical Information

Large Language Models for Improving Human-AI Collaboration

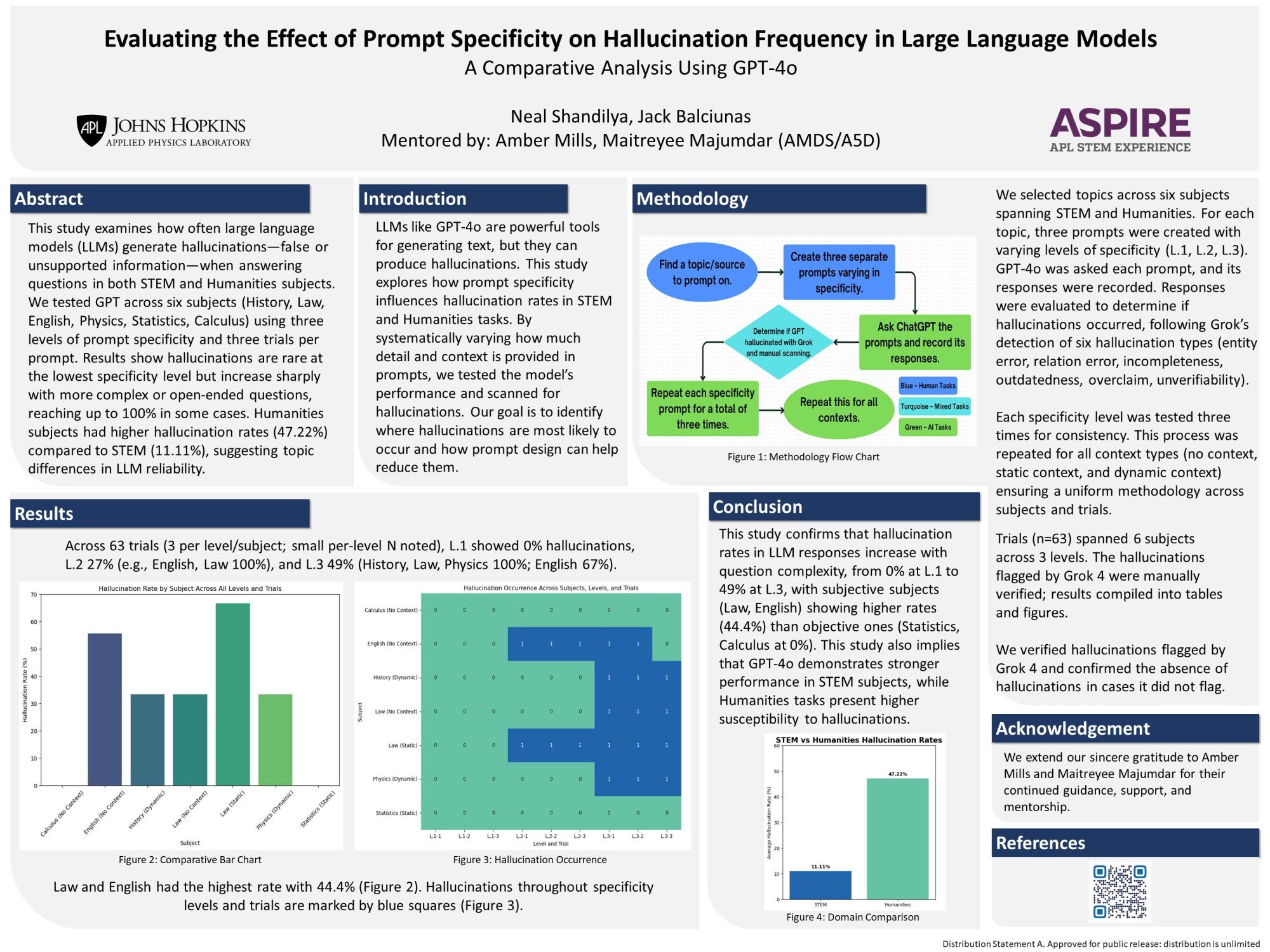
Prompted to Lie? Evaluating How Prompt Specificity Influences Hallucinations in Large Language Models

Intelligence with Integrity: Policy Guidelines for Responsible AI Systems

AI Wargaming for Future Command and Control in ARMA 3 Simulation

Modeling the Spread of Rumors in Social Networks Using LLMs

Detecting adversarial backdoor attacks on computer vision systems

Predictive Macroeconomic Trends Using Large Language Models

Creating an Reconnaissance Blind Chess Bot using Agentic AI

Parking Spotter Upgrades

LLM-Driven Embodied AI Task Generation via Genesis

A Data Processing Pipeline to Enable Machine Learning

SCENT-AI: An AI Agent that plays Foxhound Through Fog

Understanding AI Models for Global Weather Forecasting

Leveraging Large Language Models for Robotic Control

Applying Transformers to Recognize American Sign Language: An Odyssey

Agentic AI for Collaborative Problem Solving

LLM-Assisted Agentic Market Analysis (LLAAMA)

Synthetic image generation and discrimination from NIST GenAI challenge

STEM Communications and Education

GPT-Generated Health Visuals

Artificial Intelligence and STEM Education

SciOly PrepBot: An Agentic AI Framework for Creating Practice Tests

Modeling Music Listening Behaviors Spread Using Graph Theory

Other

REACT II: Researching Eye Tracking to Assess Community Trust

Images for the Artemis III Mission: Assessing Field Test Images Collected by Astronauts